Data Mesh in Practice: The Socio-Technical Reality of Owning Data Products
April 20, 2026
Data Mesh promises scalability, domain ownership, and faster data-driven development. But once you start working with it, you realize something quickly: the hardest problems are no longer technical.
As a data product owner in a data mesh environment, I’ve found that building pipelines is often straightforward. The real challenge is defining responsibilities, aligning with business stakeholders, and managing dependencies between data products. In this article, I share practical lessons from implementing data mesh in a real-world setting — and how it fundamentally changes the way teams work with data.
In a traditional data warehouse, everything is centralized. If you need a dataset, you search for it, explore it, and integrate it into your workflow. Data mesh changes this model completely. Data is no longer sitting in a central pool waiting to be discovered — it is owned by domain-specific data products. When you need data from another domain, you depend on that product’s availability, its quality standards, and the priorities of its owners.
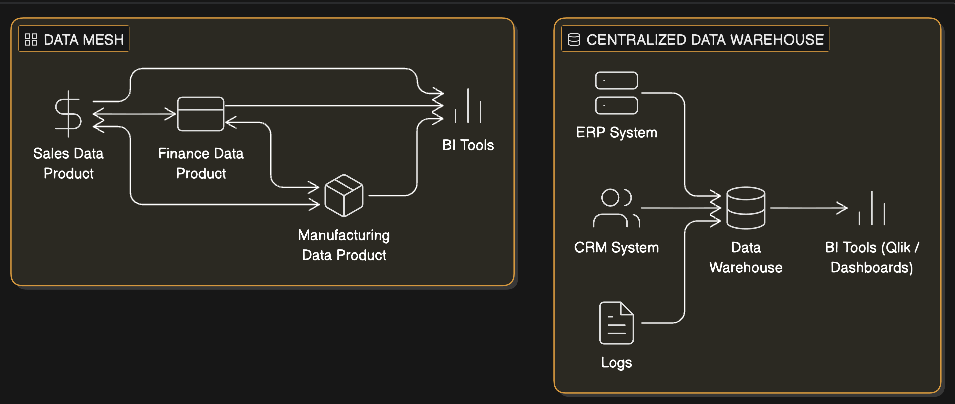
Figure: Comparison between domain-oriented data mesh and centralized data warehouse architecture.
This shift has a direct impact on how requirements are defined. In a centralized setup, vague requirements are often manageable — you can explore the data and gradually refine your understanding. In a data mesh, that approach breaks down. Because data is distributed across products, you can no longer browse your way to the right dataset. Instead, you need to be precise upfront: what data you need, including fields, granularity, and refresh frequency; which domain owns it; how it is exposed, whether through APIs, exports, or contracts; and who is responsible for maintaining it. This pushes responsibility upstream. Unclear requirements no longer just slow things down — they create real misalignment and delays.
At the same time, data mesh introduces a new kind of risk: uneven ownership. In theory, every data product has a committed owner. In practice, priorities differ across domains. A common situation is when a data product is critical for another domain, but not particularly important for its own team. In these cases, the data may receive less attention, fall behind on maintenance, and eventually become a bottleneck for dependent teams. These dependencies are not technical — they are organizational. And they are often invisible until they start causing problems.
How teams are organized matters more than most data mesh discussions acknowledge. When a dedicated team owns multiple data products within a domain, things tend to work. Collaboration happens naturally, ownership is clear, and there's enough capacity to respond to other teams' needs. When a single person owns a data product—often as a side responsibility—challenges multiply, like limited bandwidth for improvements, slow response to requests from dependent teams and weaker accountability for shared data quality.
Data mesh isn’t just an architectural decision — it’s a team design problem. The complexity shifts from systems to communication: while technical pipelines often become simpler, coordination between teams becomes significantly harder.
Data mesh is often presented as a technical solution for scaling data platforms. In practice, it represents a fundamental shift in how teams collaborate, communicate, and take responsibility for data. Understanding this early — before focusing too much on tools and architecture — can help teams avoid many of the challenges that arise when moving from centralized systems to domain-oriented data products.